Supervised learning is fundamental in AI/ml, where systems are trained using labeled examples and learn to make predictions. This is teaching algorithms to identify a pattern, using old data, so it can determine what happens next. From predicting the price of a house to classifying images, supervised learning is behind many AI applications we come across daily.
In this piece, we’ll take a look at what the supervised learning algorithms are, how they work and some real-world applications of them, and we will also discuss the importance of these algorithms to today’s technology.
How Does Supervised Learning Work?
The way that supervised learning works, you have input features and output labels in your dataset. These labeled pairs inform the model of what it already know is the correct answer and enable it to capture patterns from the data. After training, this model can then be used to predict the outcome of new, previously unseen input data.
The Basics of Supervised Learning
The word “supervised” in supervised learning helps the algorithm to learn as it is being taught by a teacher (the labelled data). This teacher feeds the algorithm its input (features) and correctly chooses which output (label) to give to it. As data is fed through the algorithm, it establishes a correlation between the inputs and outputs and works on improving its knowledge over time.
For instance, imagine you have a model trained to predict house prices on the basis of properties like its size, location and number of bedrooms. The algorithm will figure out patterns within the features, relating to pricing and can apply this knowledge to future house prices.
Training vs. Testing Data
The performance of the model can assessed by splitting up the dataset into training data and testing data. The training data trains the algorithm and testing gives measure of how well does that model generalizes to new, never seen examples. This split makes the model never overfit to the data, but only memorizes them and learns meaningful features. Which can be generalized in real world situation.
Types of Supervised Learning Algorithms
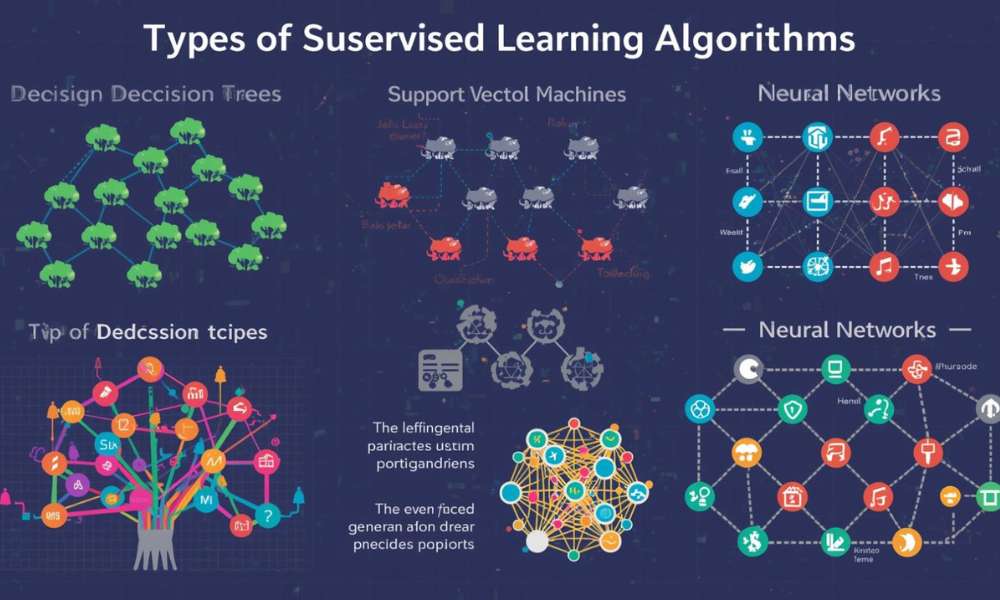
Supervised Learning is a vast area, and there are different algorithms which cater to variety of problems. Here are some of the most popular supervised learning algorithms.
Linear Regression
Linear regression is an estimation for predicting continuous outcomes. It models the relationship between a set of input variables (features) and a continuous target. For instance, predict the price of a house based on features such as square footage or number of rooms.
Logistic Regression
The logistic regression is designed to handle binary classification tasks, which means the output is a prediction of one of two things. So for example, whether an email is spam or not whether a company will go bankrupt.
Decision Trees
Classifying and regressing with decision trees. These models take a decision by dividing the data into branches on varying feature values. The result is a prediction tree.
Support Vector Machines (SVM)
SVM is a robust classification model that maximally separates samples based on the discovery of the best dividing hyperplane. It is frequently used in image recognition and text classification.
K-Nearest Neighbors (KNN)
kNN is a basic algorithm that labels data points according to their surrounding neighbors. It is increasingly used for classification problems, like identifying handwritten digits.
Naive Bayes
Naive Bayes is a probabilistic algorithm for performing classification, particularly with text data. It works under the assumption of feature-independence and leverage Bayes’ theorem to predict probability of occurence of different events.
Data’s Role in Supervised Learning
Data is paramount in a supervised setting – it forms the basis of learning. The higher-quality, more varied the data an algorithm sees, the better it can understand complex patterns and make accurate predictions. Also, data annotation is the cornerstone of this process since labeled data acts as a “teacher” for the algorithm.
Data Labeling
Data labeling entails tagging each datapoint with the right output. This labeled data is the input that a given algorithm needs to learn from examples. Without good labeling, the algorithm would have a hard time making any sort of useful predictions.
In image classification, for instance, you would have to label a dataset of photographs as “cat” or “dog” before the algorithm can learn how to identify animals in other images.
Evaluating Supervised Learning Models
Once the model has been trained. It’s essential to evaluate its performance using various metrics to ensure it’s making accurate predictions. Some key evaluation metrics include:
- Accuracy: The percentage of correct predictions made by the model.
- Precision and Recall: These metrics are especially useful for imbalanced datasets. Where one class is underrepresented.
- F1 Score: A combined measure of precision and recall, offering a balance between the two.
Cross-Validation
To avoid overfitting, where a model performs well on training data but poorly on new data, cross-validation is used. This technique involves splitting the dataset into multiple subsets, training the model on some of them, and testing it on others. Also, this helps ensure that the model’s performance is consistent across different data points.
Applications of Supervised Learning
Supervised learning algorithms have widespread applications in various industries. Here are just a few examples of where this technology is used:
- Email Filtering: Supervised learning algorithms help detect spam emails by learning from labeled examples of spam and non-spam emails.
- Healthcare: In medicine, these algorithms can predict patient outcomes based on historical medical data.
- E-commerce: Online stores use supervised learning to recommend products based on a customer’s browsing and purchasing history.
- Financial Services: Banks use these algorithms to assess credit risk, detect fraud, and predict market trends.
Challenges in Supervised Learning
While supervised learning is powerful, it does come with some challenges. Here are a few common issues:
- Overfitting: This occurs when the model is too complex and learns the noise in the data rather than the underlying pattern.
- Imbalanced Data: When one class is significantly underrepresented, the algorithm may struggle to learn the minority class effectively.
- Data Quality: The performance of supervised learning models heavily relies on the quality of the labeled data. Poor-quality data can lead to inaccurate predictions.
Conclusion
Supervised learning algorithms are transforming industries by enabling machines to make intelligent decisions based on historical data. From healthcare to e-commerce, the ability to predict outcomes and recognize patterns is essential for innovation in today’s digital age.
As AI continues to evolve, supervised learning will only become more accurate and efficient, with improvements in data quality, algorithm sophistication, and computational power. Whether you’re working in finance, marketing, or any other field, understanding how supervised learning works can help unlock new possibilities and drive better decision-making processes.
Embracing these technologies will help individuals and organizations stay ahead in a world where data-driven insights are becoming increasingly vital.